하이브리드 엔진의 질서: 아키텍처의 물리적 재설계
엔비디아가 대규모 멀티 에이전트 연산을 처리하는 네모트론 3 슈퍼(오픈소스 LLM)를 정식 출시했다. 시스템은 입력 데이터를 100만 토큰의 컨텍스트 윈도우(상태 보존 메모리)로 수집하여 Mamba-Transformer 레이어(하이브리드 구조)**로 전달한다. 이후 Latent MoE(매개변수 라우터)**가 1200억 개의 전체 파라미터 중 120억 개만 활성화하여 연산을 분배한다. 출력 단계에서는 MTP 기술(다중 토큰 예측)**이 다수의 토큰을 동시 생성하여 지연을 줄인다. 이 물리적 흐름은 기술 부채를 감소시키고 스택 최적화를 달성한다.
| 항목 | 네모트론 3 슈퍼 | 기존 독점 아키텍처 |
| 연산 구조 | MoE(매개변수 라우터) | 밀집형(Dense) |
| 활성 규모 | 120억 개 | 전체 파라미터 |
| 데이터 정밀도 | NVFP4(저정밀도 포맷) | FP8 |
**Mamba-Transformer 레이어(하이브리드 구조): Mamba-Transformer는 트랜스포머의 어텐션 메커니즘과 맘바의 SSM(상태 공간 모델)을 결합한 하이브리드 구조다. 트랜스포머는 전역적 문맥 파악에 능하지만 시퀀스 길이에 따라 연산량이 급증하는 한계가 있다. 반면 맘바는 선형적 복잡도로 데이터를 처리하여 추론 속도가 빠르다. 이 레이어는 두 구조를 교차 배치함으로써 긴 문맥 유지 능력과 연산 효율성을 동시에 확보한다. 특히 대규모 언어 모델에서 메모리 사용량을 최적화하고 처리 속도를 극대화하는 데 기여한다.
일반적으로 트랜스포머의 어텐션 블록(Attention Block)과 맘바의 SSM 블록(State Space Model Block)을 수직적으로 교차 배치하거나 특정 비율로 인터리빙(Interleaving, 엇갈리게 배치하거나 교차로 끼워 넣는 기법)하는 설계를 채택한다. 이는 어텐션 메커니즘의 정교한 전역 문맥 파악 능력과 맘바의 선형적 연산 효율성을 아키텍처 레벨에서 통합하기 위함이다. 즉, 하이브리드 설계를 통해 각 모델의 물리적 한계를 상호 보완하는 구조를 형성한다.

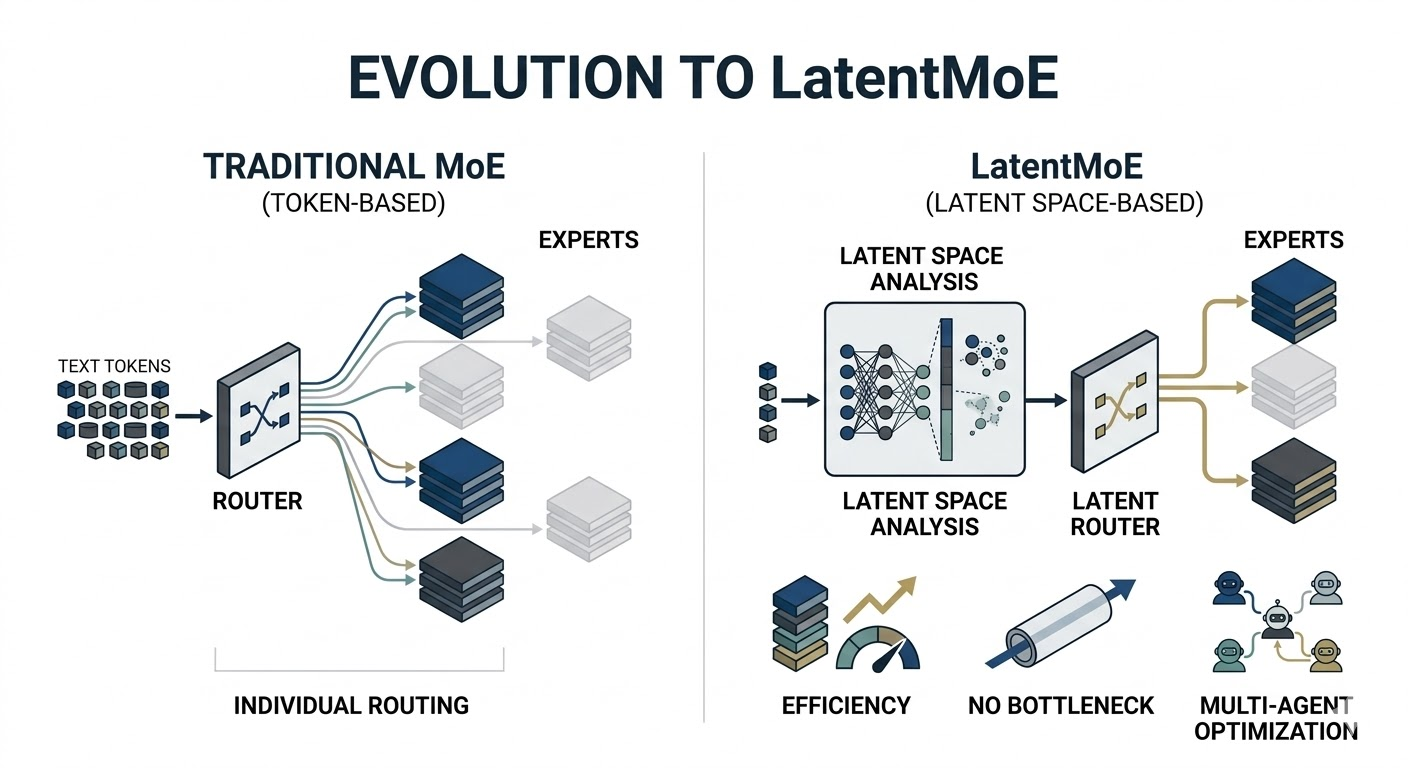
**Latent MoE: Latent MoE는 Mixture-of-Experts(MoE)의 진화된 형태로, 입력을 최적의 전문가(Expert) 모델로 배분하는 매개변수 라우터다. 기존 MoE가 개별 토큰 단위로 라우팅을 수행했다면, Latent MoE는 잠재 공간(Latent Space)에서 특징을 분석하여 연산을 분배한다. 이 구조는 전체 파라미터 중 극히 일부만 활성화(희소 활성화)하여 연산 효율을 극대화하고 메모리 대역폭 병목을 해소한다. 특히 멀티 에이전트 환경에서 작업 특성에 맞는 전문가를 정교하게 선택하여 추론 속도를 높이고 시스템 부채를 줄이는 핵심 역할을 수행한다.
**MTP 기술(다중 토큰 예측): 기존 LLM은 한 번에 하나의 토큰만 생성하는 자기회귀 방식을 사용한다. 반면 MTP 기술은 병렬 예측 헤드를 통해 다음 이어질 여러 개의 토큰을 동시에 예측하여 생성한다. 이는 전체 추론 단계 수를 줄여 응답 지연 시간을 획기적으로 단축한다. 특히 긴 문장을 생성하거나 복잡한 에이전트 간의 빠른 피드백이 필요한 환경에서 병목 현상을 해소하는 핵심 기술이다. 하드웨어 연산 자원을 효율적으로 사용하여 초당 토큰 처리량을 극대화함으로써 실시간 서비스 품질을 향상시킨다.
팽창하는 지능의 궤적: 나노에서 슈퍼로의 진화
네모트론 시리즈는 파라미터 활성화 비율을 조정하여 연산 효율을 확보하는 방식으로 진화했다.
- 2024년: 기초 단위의 에이전트 제어를 위한 초기 모델 구조 확립 및 내부 훈련 데이터세트 구축 완료.
- 2025년: 네모트론 3 나노(소형화 엣지망) 배포. 300억 개 파라미터 체급으로 실시간 지연 시간 단축 달성.
- 2026년: 네모트론 3 슈퍼(오픈소스 LLM) 정식 출시. NVFP4(저정밀도 포맷) 도입으로 기존 대비 5배의 처리량 향상 달성. 하반기 울트라 버전(초거대 추론망) 출시 예정.
생태계의 지각변동: 병목 현상을 해소하는 파괴적 혁신
이 아키텍처는 에이전틱 AI 생태계의 연산 지도를 재배열한다. 120억 개의 파라미터만 선별적으로 점유하는 구조적 원리는 추론 과정의 연산량을 급감시킨다. 결과적으로 VRAM 대역폭 한계로 촉발되던 시스템 병목 현상이 해소된다. 엔지니어는 NIM(마이크로서비스)을 활용하여 기존 인프라에 모델을 즉각 마운트**한다. 이는 상호운용성을 극대화하여 엔터프라이즈 환경의 시스템 안정성을 대폭 향상시킨다. 또한 내부 가중치와 NeMo Gym(강화학습 환경)이 개방되어 오픈소스 생태계 전반의 개발 생산성이 수직 상승한다.
**NIM(마이크로서비스)을 활용하여 기존 인프라에 모델을 즉각 마운트: NIM(NVIDIA Inference Microservices)은 모델, 추론 엔진, 표준 API를 단일 컨테이너로 패키징한 추론 최적화 서비스다. 인프라에 모델을 즉각 마운트한다는 것은 복잡한 최적화 과정 없이 도커나 쿠버네티스 환경에 플러그 앤 플레이 방식으로 결합함을 의미한다. 이를 통해 개발자는 표준화된 인터페이스로 AI 기능을 제어하며, 하드웨어 가속 성능을 즉시 확보하고 시스템 간 상호운용성을 극대화한다.
실전 배치의 정석: 산업 현장을 관통하는 연산 전략
복잡한 분기 처리가 필요한 시스템에서 기술 도입이 증가한다. 다쏘시스템은 제조 파이프라인에 본 아키텍처를 연동하여 공정 배치 과정을 재조정했다. 다수의 모듈이 데이터를 교환하는 환경에서 100만 토큰의 메모리 할당이 문맥 이탈을 방지**한 결과다. 서비스나우는 IT 티켓 자동화 시스템에 이를 결합하여 텍스트 분류 속도를 높였다. 퍼플렉시티는 검색 질의 라우팅에 적용해 데이터 추출의 일관성을 확보했다. 이는 인프라 전환으로 유지보수 효율성을 개선한 물리적 사례다.
**다수의 모듈이 데이터를 교환하는 환경에서 100만 토큰의 메모리 할당(컨텍스트 윈도우)이 문맥 이탈을 방지: 제조 파이프라인은 설계, 해석, 공정 등 다양한 모듈이 방대한 데이터를 실시간으로 교환하는 복잡한 구조다. 기존의 짧은 컨텍스트 윈도우는 데이터를 분절하여 처리해야 하므로 초기 설계 사양을 망각하거나 모듈 간 상충하는 명령을 내리는 문맥 이탈 현상이 빈번했다. 네모트론 3 슈퍼의 100만 토큰 메모리 할당은 수천 페이지의 기술 문서와 복잡한 시뮬레이션 데이터를 한 번에 수용한다. 이는 전 공정의 인과관계를 단일 연산 내에 유지하여 설계 의도의 일관성을 보존하고 시스템 전반의 무결성을 확보한다.
표준화의 사투: 향후 10년의 전망과 제어 전략
향후 5년 내 다중 에이전트 워크플로우의 통신 표준으로 기능할 전망**이다. 물리적 하드웨어의 대규모 증설 없이 단일 장비에서 연산을 분산 처리하여 기술 진입 장벽을 낮춘다. 단, MoE(매개변수 라우터) 활성화가 유동적으로 유발하는 전력 소비 스파이크 현상은 아키텍처의 리스크로 남는다. 이를 제어하기 위해 LoRA(파라미터 최적화) 기반의 가중치 미세조정을 결합하는 기술 전략이 필요하다. 모듈 라우팅을 고도화하여 온프레미스 인프라의 확장성을 선제적으로 확보해야 한다.
**다중 에이전트 워크플로우의 통신 표준으로 기능할 전망: 엔비디아가 NIM(마이크로서비스)을 통해 표준화된 API 인터페이스를 제공하기 때문이다. 네모트론 3 슈퍼의 100만 토큰 컨텍스트는 여러 에이전트 간의 복잡한 대화 기록을 손실 없이 공유하는 공통 메모리 역할을 수행한다. 또한 Latent MoE가 작업 특성에 따라 전문가를 라우팅하는 메커니즘은 에이전트 간 업무 분담과 통신의 논리적 규격을 정립한다. 엔비디아의 인프라 지배력을 바탕으로 한 이 소프트웨어 스택은 다중 에이전트 협업의 사실상 표준으로 안착할 가능성이 높다.

'IT&Tech' 카테고리의 다른 글
| 데이터 파이프라인 생존 조건: CSV, JSON, Parquet, Avro 파일 포맷 (0) | 2026.03.25 |
|---|---|
| 데이터 레이크하우스의 필수 지도, 데이터 카탈로그 (0) | 2026.03.24 |
| 클라우드 컴퓨팅 칩셋 3대장: Intel, AMD, Arm 비교 (0) | 2026.03.07 |
| Groq LPU: 초고속 추론을 위한 SRAM 중심의 아키텍처 (0) | 2026.03.04 |
| 우주 데이터센터의 생존을 결정하는 극한 냉각 아키텍처 분석 (0) | 2026.02.28 |